Exploration of Recommendation Systems
BU's EC 503 Class Project Submission.
- Dataset Used
- Tools Used
- Hyperparameters Used
- Data-Preprocessing
- Experiments
- Results
- What we learned?
- References :
Dataset Used

-
Books Recommendation Dataset
-
Artificial Dataset
Tools Used
-
Python Programming language to perform experiments.
-
Used Sklearn for Modelling SVD.
-
Used Gridsearch for performing hyperparameter tuning.
-
Used matplotlib library to build various plots to analyze and showcase the results of experiments.
-
Pandas and Numpy to perform data-preprocessing
Hyperparameters Used
-
Training and Testing Split: 80%, 20%
-
num_of_components or top ‘r’ singular values =250
-
iterations=20
Data-Preprocessing
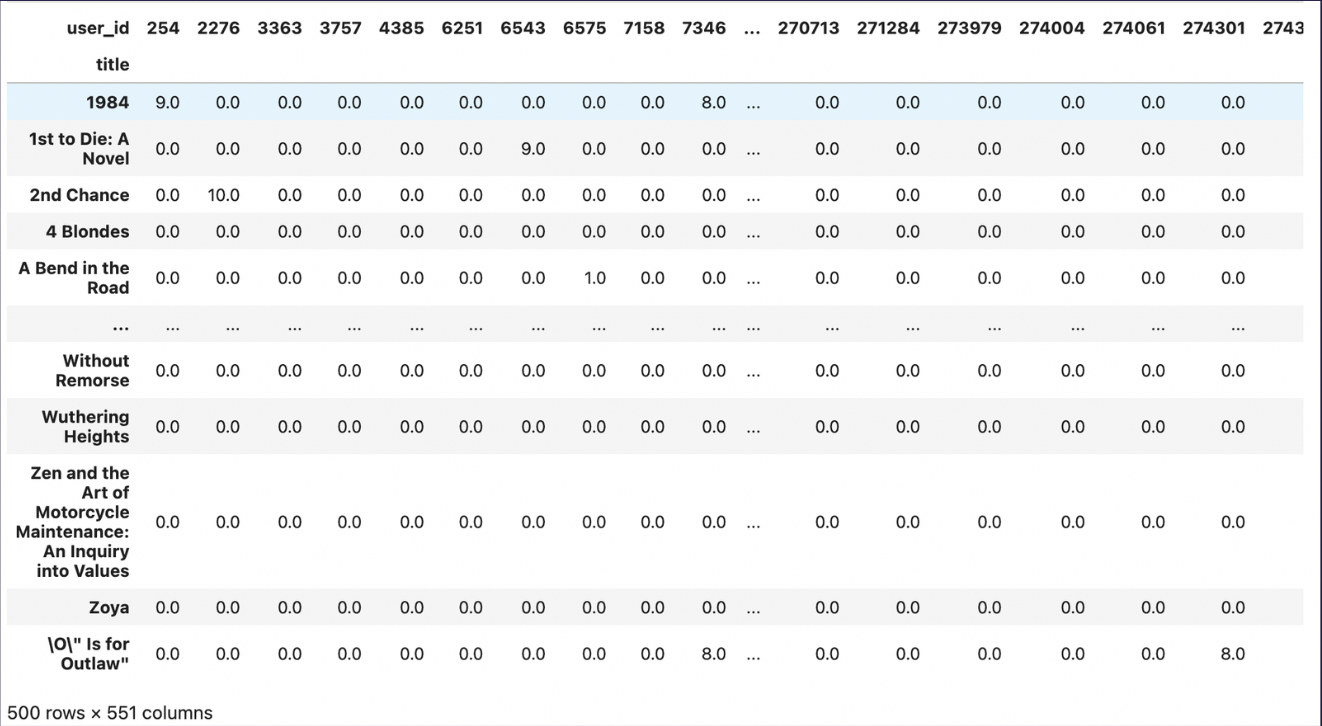
- Dataset is 97% sparse.
- Ratings: (1-10)
- Final Shape (500, 551) –> (Users, Books) Rating Matrix
-
Ensured the Users have at least rated more than 300 books
-
Ensured the Books had at least 50 ratings from users
-
Fill Empty/NAN(Not a Number) values with zeros.
-
Remove duplicates(ensures unique users and books)
Experiments
Experiment 1: Finding Best Filling Method for Dealing with Missing Values in Sparse Matrix
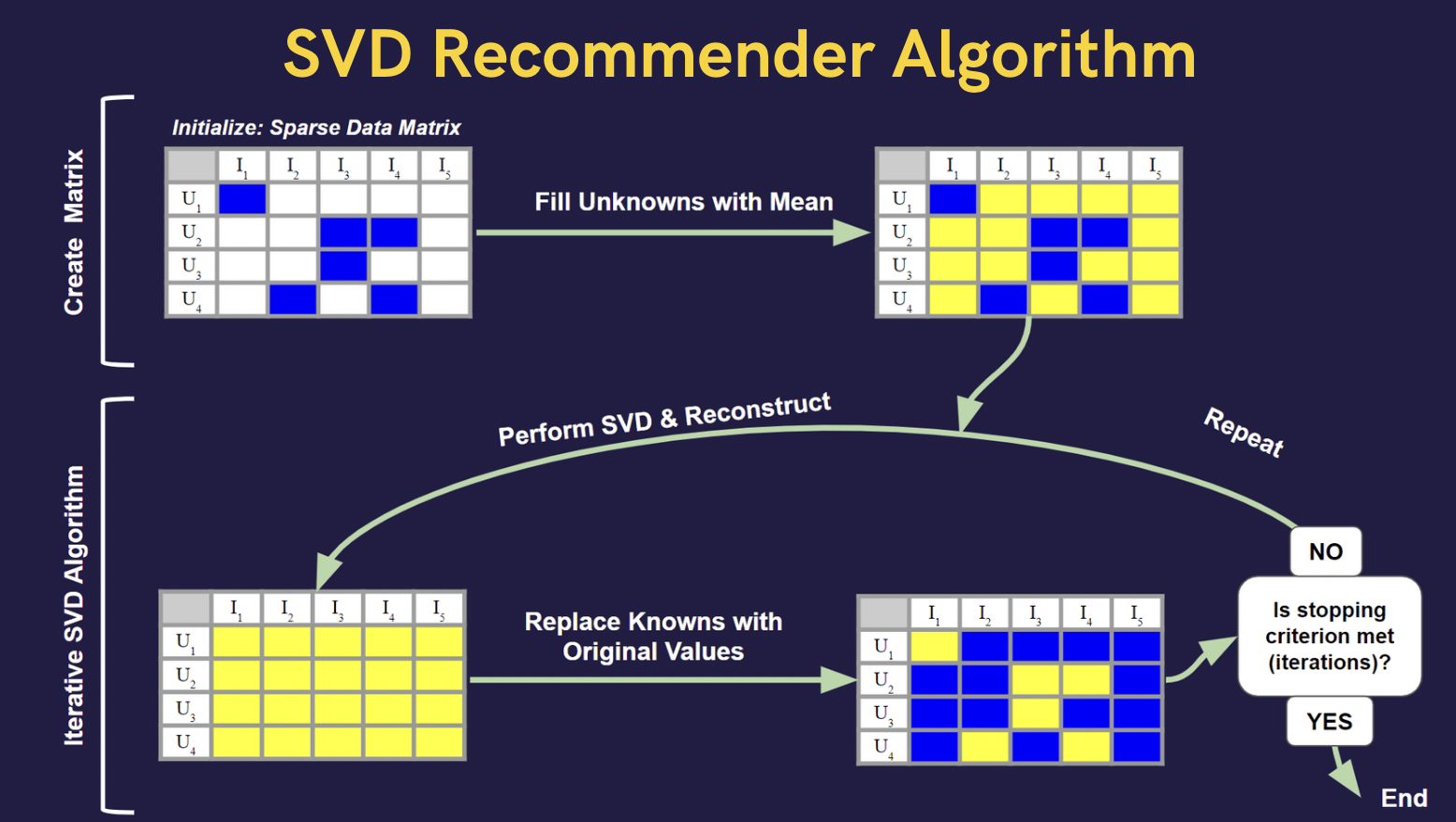
1. Step 1: Create the User-Book Sparse matrix : Fill unknowns with:
-
zeroes
-
column mean per user
-
row mean per book
-
column median per user
-
row median per book
2. Step 2: Singular Value Decomposition (SVD): Perform SVD on the sparse matrix attained from Step 1 and get a low rank Approximation by using a fraction of the components (250, acquired through cross-validation) to reconstruct the User-Book Matrix
3. Step 3: Evaluate Results at every iteration Compare predicted reconstructed matrix & original matrix using RMSE, MSE, MAE, Pearson Coefficient, & Cosine Similarity
4. Step 4: Replace with original values : Substitute the known non-zero values of the original sparse matrix into the output matrix and left the rest untouched.
5. Go to Step 2 and repeat for 5 iterations.
Experiment 2: Increasing Sparsity
1. Step 1: Increase Sparsity- Set 300 random elements in the User-Book Sparse Matrix to zero
2. Step 2: Predict- Perform SVD & use a fraction of components (250 components(acquired through Cross Validation)) on the final sparse matrix from the above step to get the reconstructed matrix.
3. Step 3: Replace with original values- Substitute the known elements of the original sparse matrix into output matrix, but leave the rest untouched.
4. Step 4: Evaluate Results- Compare prediction matrix & original matrix using RMSE, MSE, MAE, Pearson Coefficient, & Cosine Similarity
5. Decreasing Sparsity Test- Repeat all the steps 2, 3, 4, 5 by First Filling 300 unknown values with mean (column wise)
Experiment 3: Artificial Dataset Creation
1. Create low-rank (250 components) reconstruction using SVD from Books-Users sparse matrix. (iterations=1)
2. Add zero-mean gaussian random noise to every element.
3. Round up to nearest integers in range 1-10.
4. Randomly drop 20% of rows & columns.
5. Increasing the sparsity on artificial dataset- Increase sparsity by 10% in every iteration (randomly setting elements to zero)
6. Perform SVD and evaluate the results.
Algorithim Used :
Results
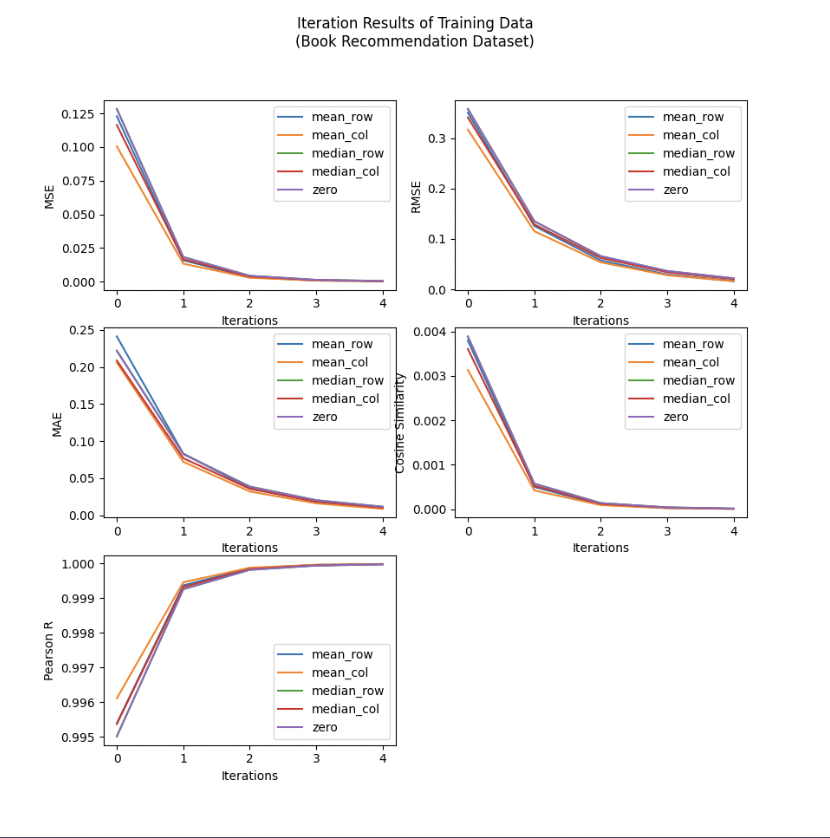
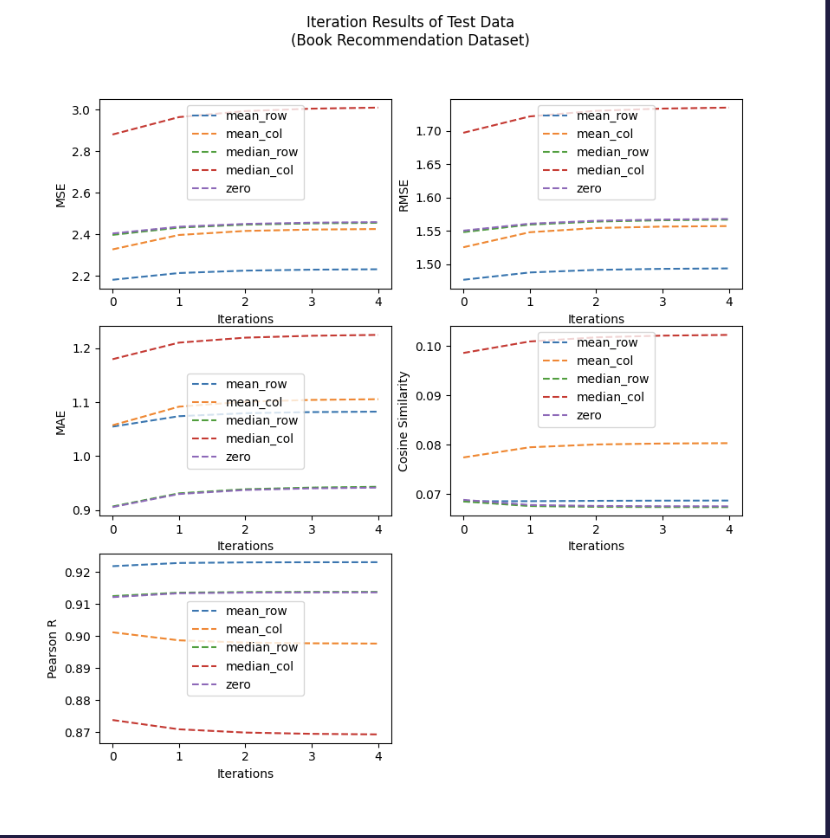
Experiment 1: Iterative Results of SVD Recommender Prediction Algorithm using Different Filling Methods(**Iterations =5**)
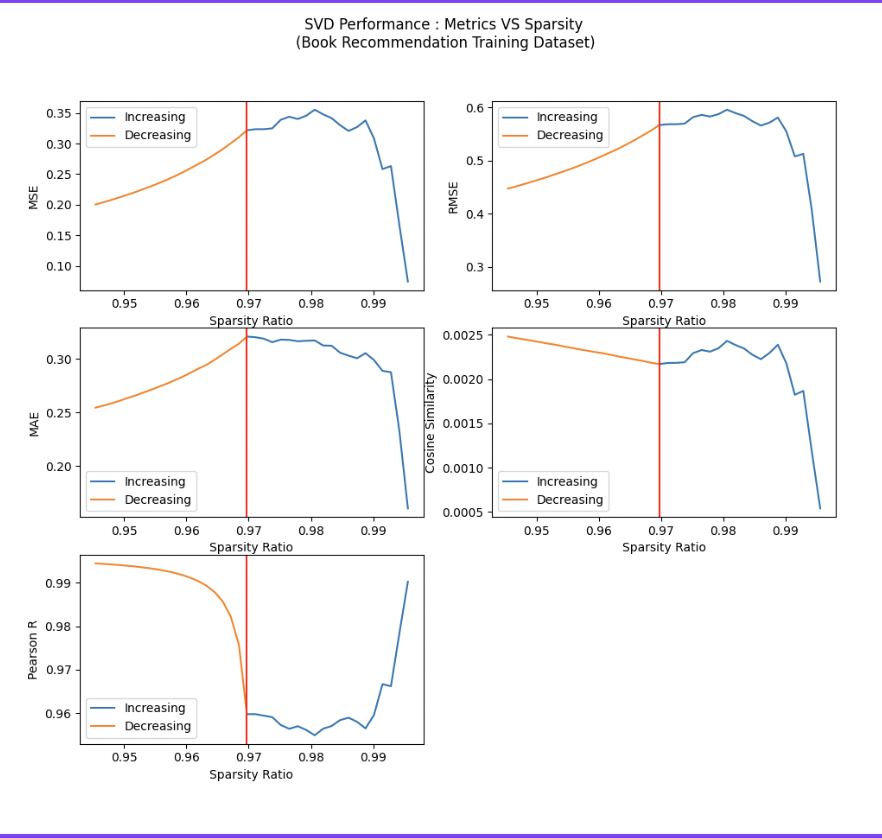
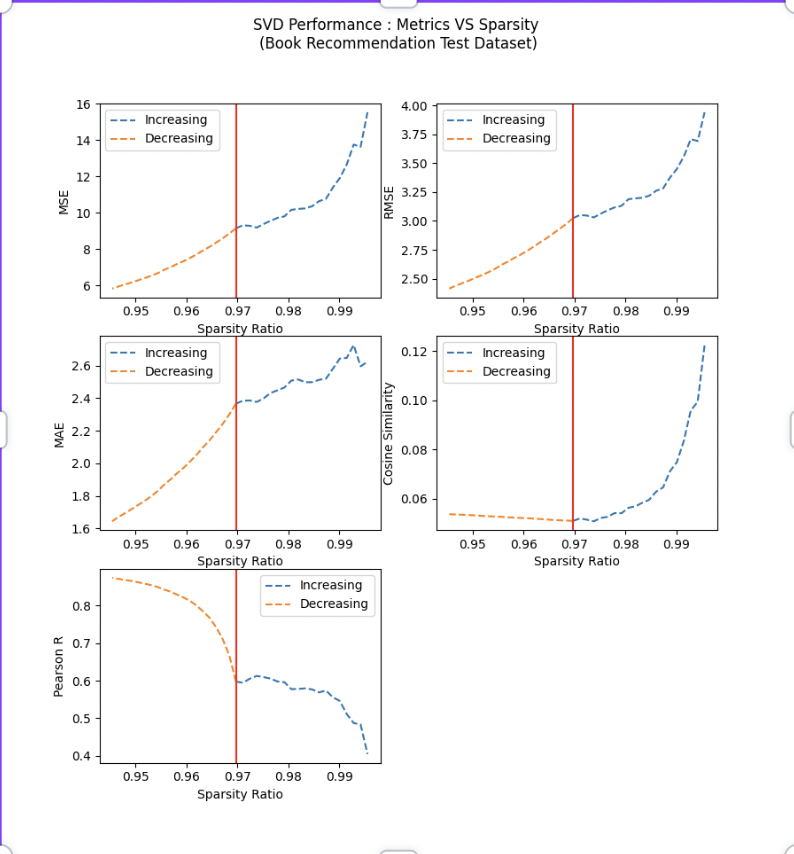
Experiment 2: Increasing & Decreasing Sparsity on User-Books Sparse Matrix(Iterations =20)
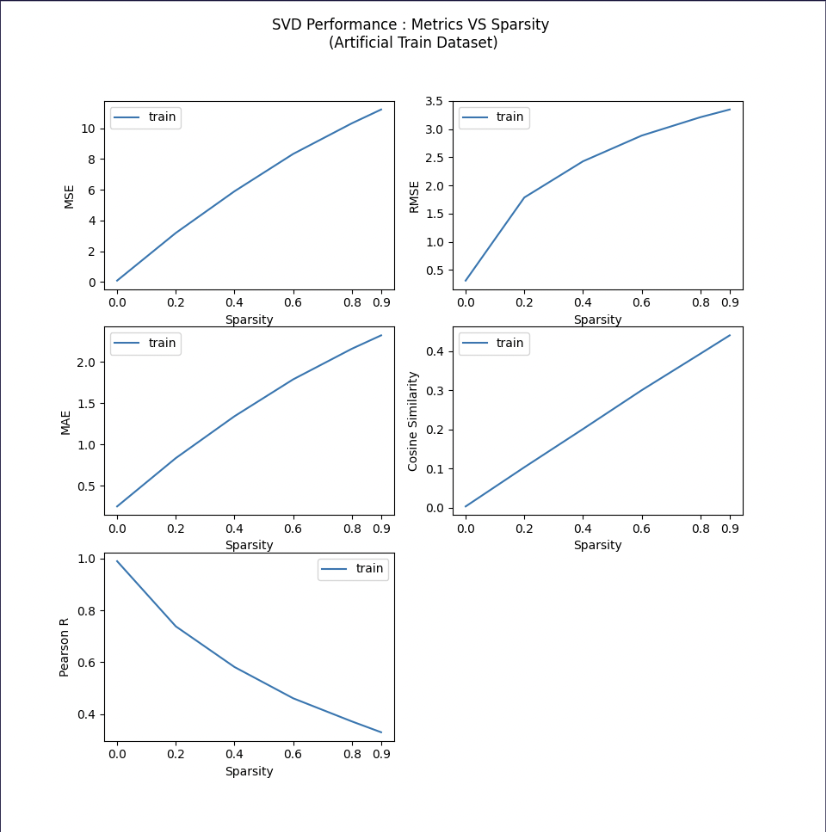
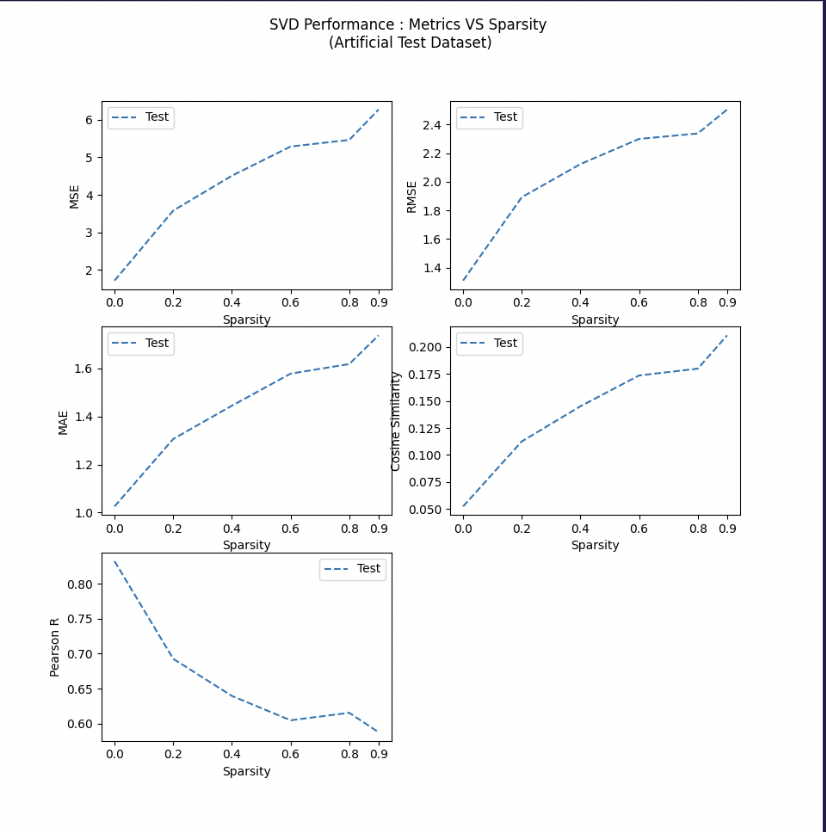
Experiment 3: Increasing Sparsity on Artifical Dataset in Range 0% - 90%
What we learned?
-
As the user-item dataset matrix becomes sparser, the recommendations become less accurate
-
Different strategies to fill in unknown values in the user-item matrix
-
Iterative SVD algorithm for recommendation
References :
1. Various Implementations of Collaborative Filtering.
3. SVD