GPT-3
Generative Pre-trained Transformer : Next Step towards AGI
- GPT-3
- Facts about GPT-3
- GPT-3 Training phase
- GPT-3 Working & Architecture
- GPT-3’s Potential Applications
- GPT-3 Limitations
- Future Scope
GPT-3
GPT-3 stands for Generative Pre-trained Transformer 3. It is a gargantuan artificial Neural Network (NN) around the size of a mouse brain, trained on essentially the whole internet and millions of and GPT-3 is a language model, which means that, using sequence transduction, it can predict the likelihood of an output sequence given an input sequence. This can be used, for instance to predict which word makes the most sense given a text sequence.
Facts about GPT-3
-
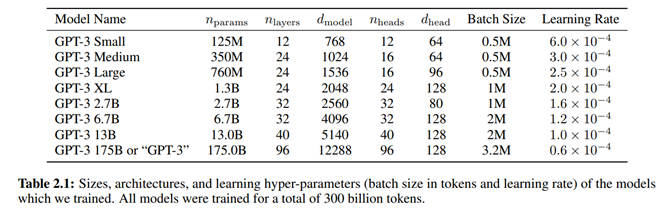
Trained on 300 Billion words has been trained using also huge datasets, including the Common Crawl dataset and the English-language Wikipedia (spanning some 6 million articles, and making up only 0.6 percent of its training data),
-
GPT-3 uses 175 Billion parameters (Previous model GPT-2 “only” used 1,5 billion parameters.)
-
96 NN Layers (more than human brain has for interactive tasks!)
-
A few $Million$ computing cost for training,but can write a whole book for $1 electricity cost.
-
Top-5 super-computer: 285’000 CPUs + 10’000 GPUs
-
Simpler works better: no encoders and no recurrence
-
GPT-3 is a Generative Pre-Trained Transformer (once only!)
-
Once trained, you prompt it with a (con)text of up to 12288 (sub)words
-
GPT-3 is not fine-tuned (adapted in any way) to different tasks
GPT-3 Training phase

The dataset of 300 billion tokens of text is used to generate training examples for the model. For example, these are three training examples generated from the one sentence at the top.
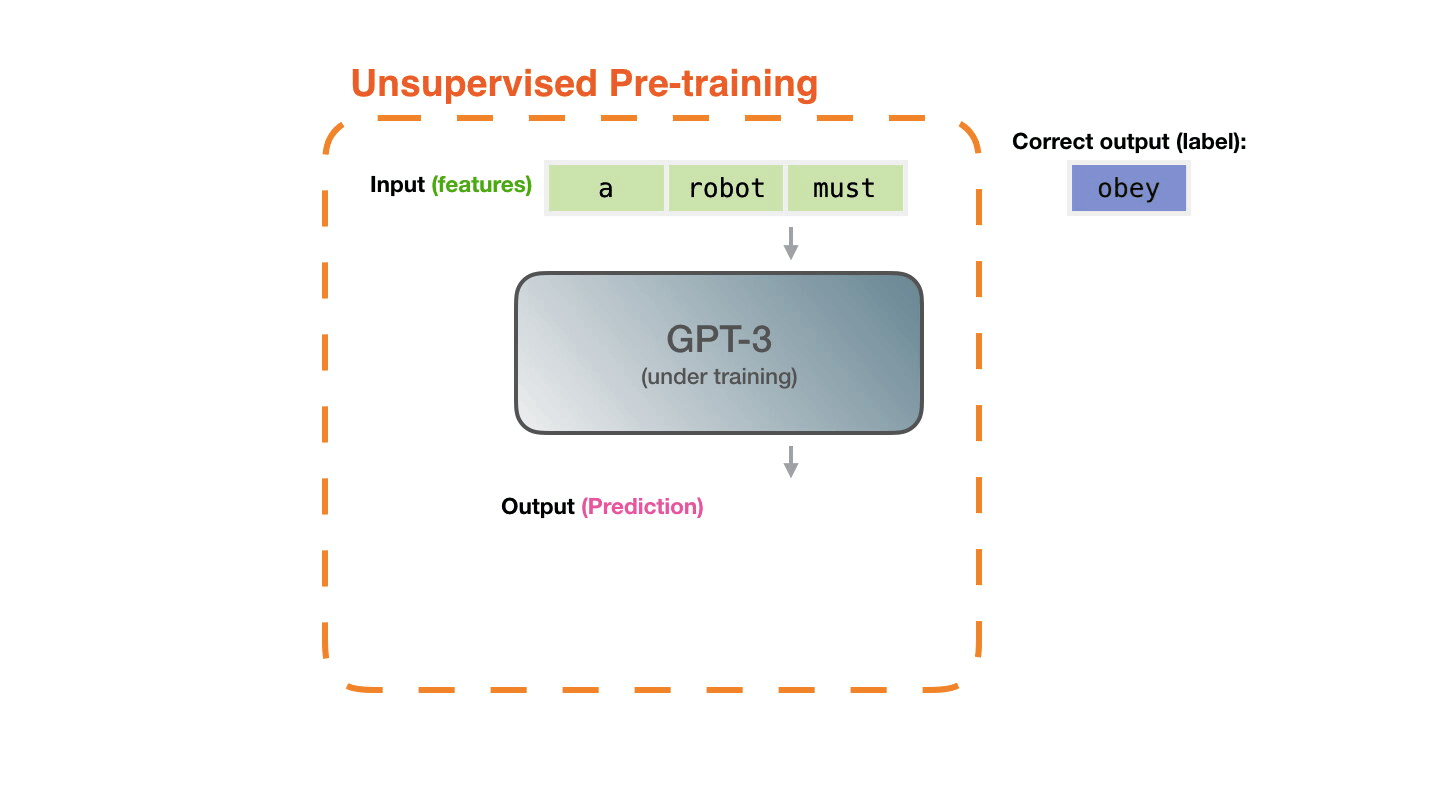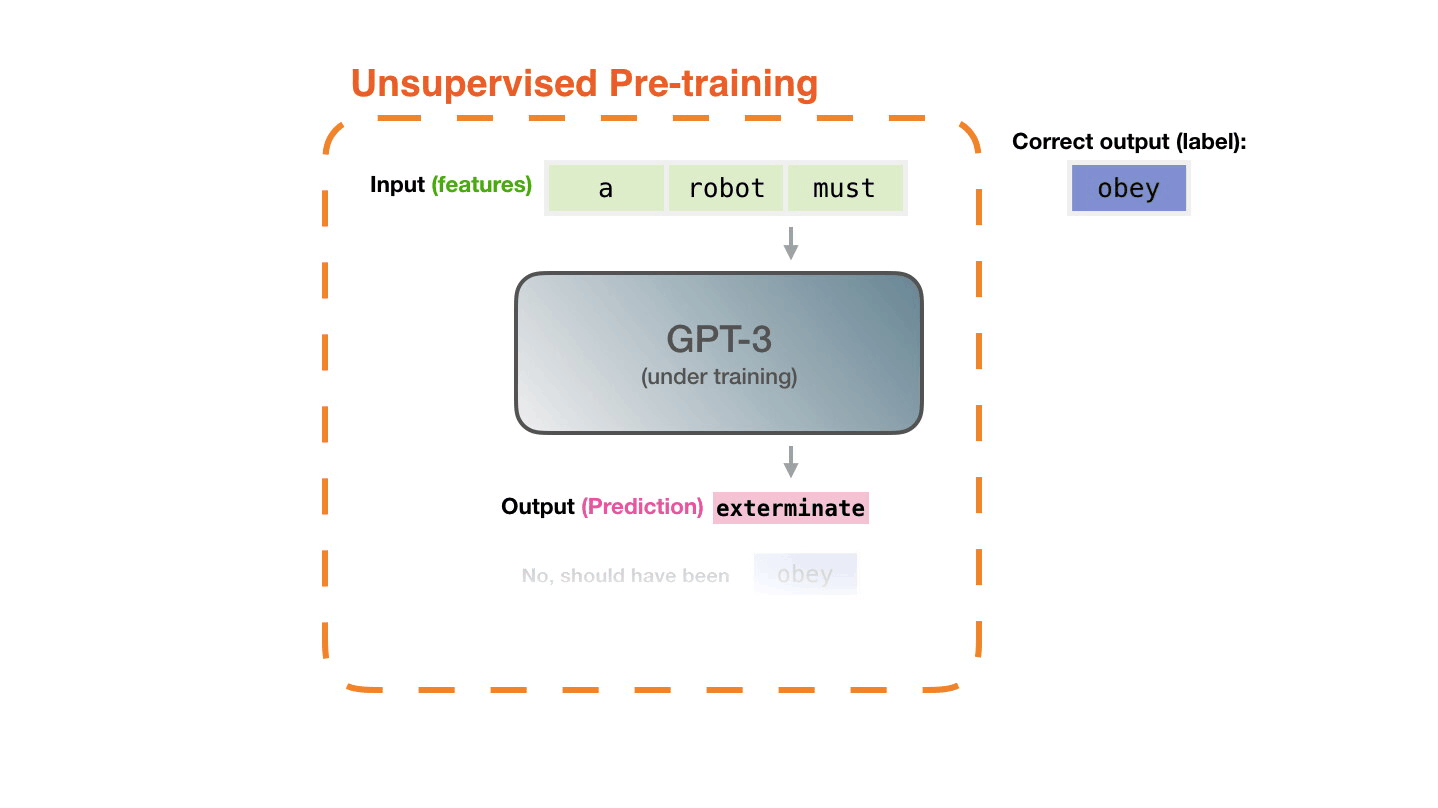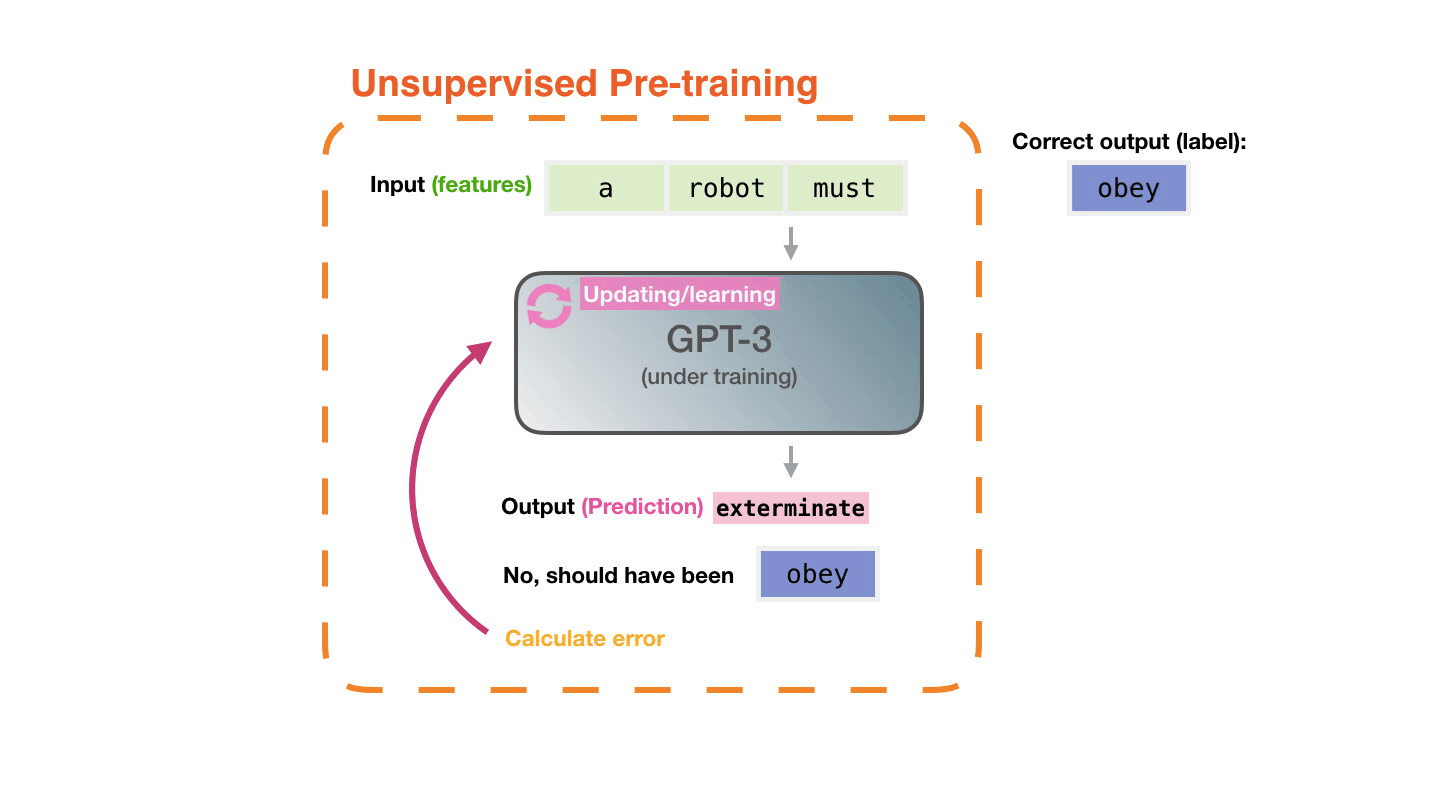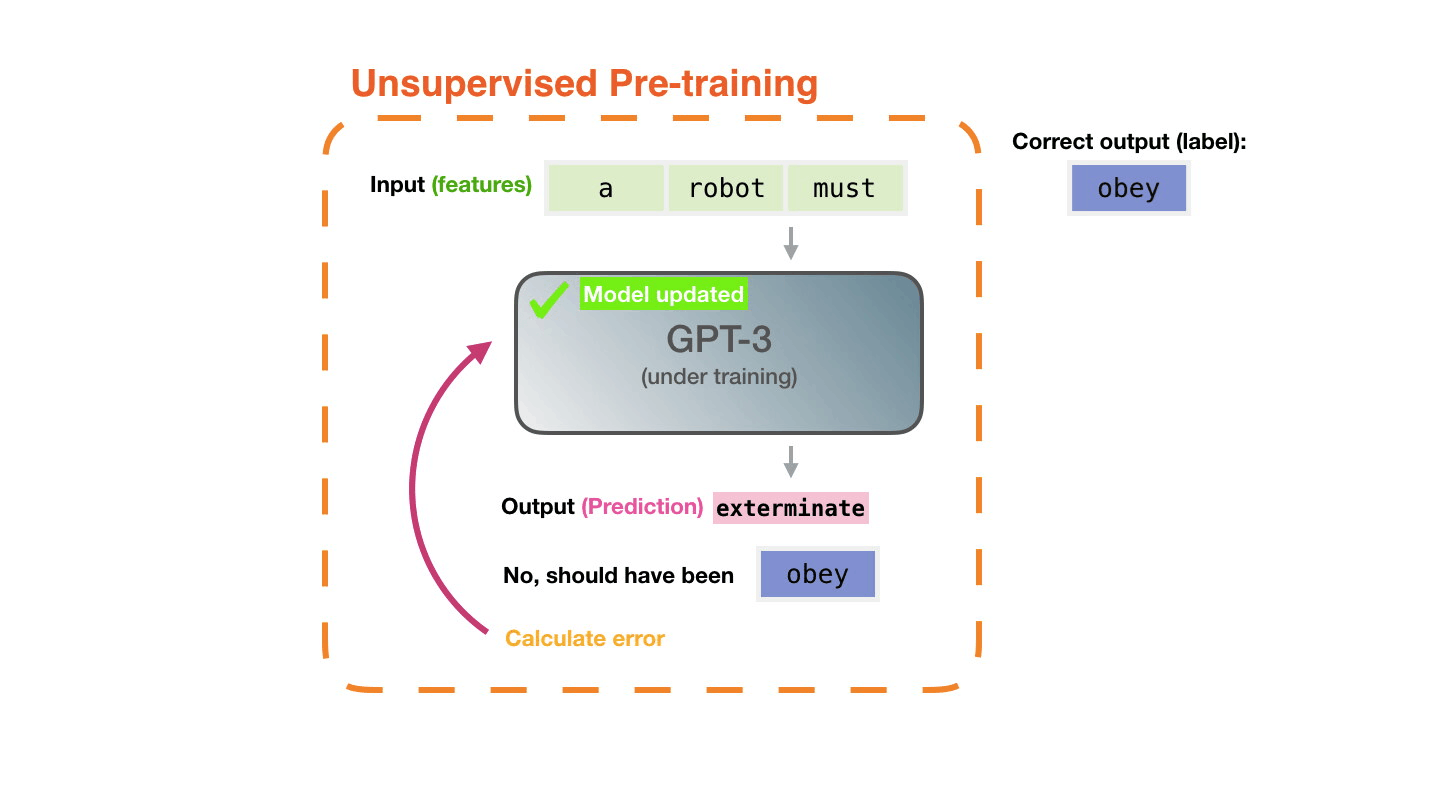
The model is presented with an example. We only show it the features and ask it to predict the next word.
The model’s prediction will be wrong. We calculate the error in its prediction and update the model so next time it makes a better prediction. Repeat millions of times
GPT-3 Working & Architecture
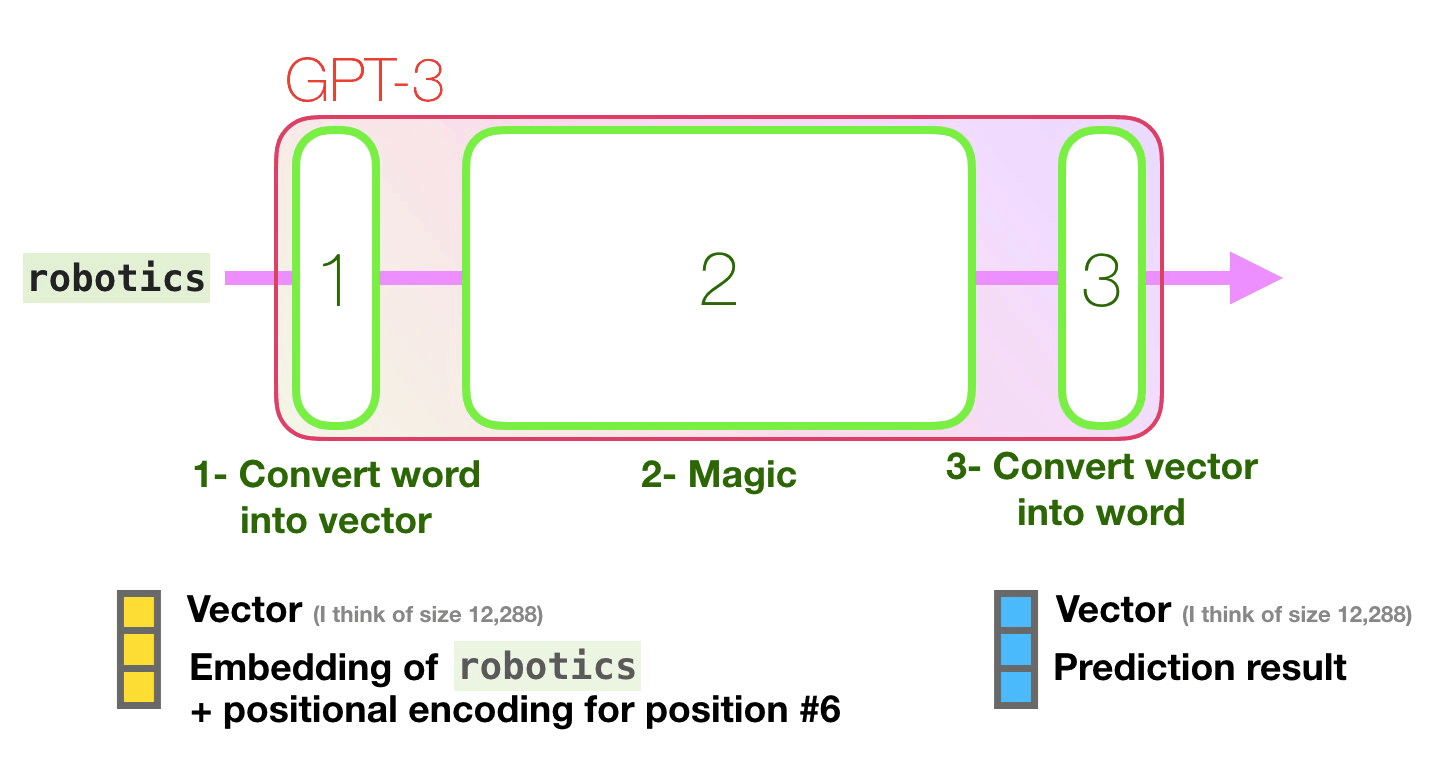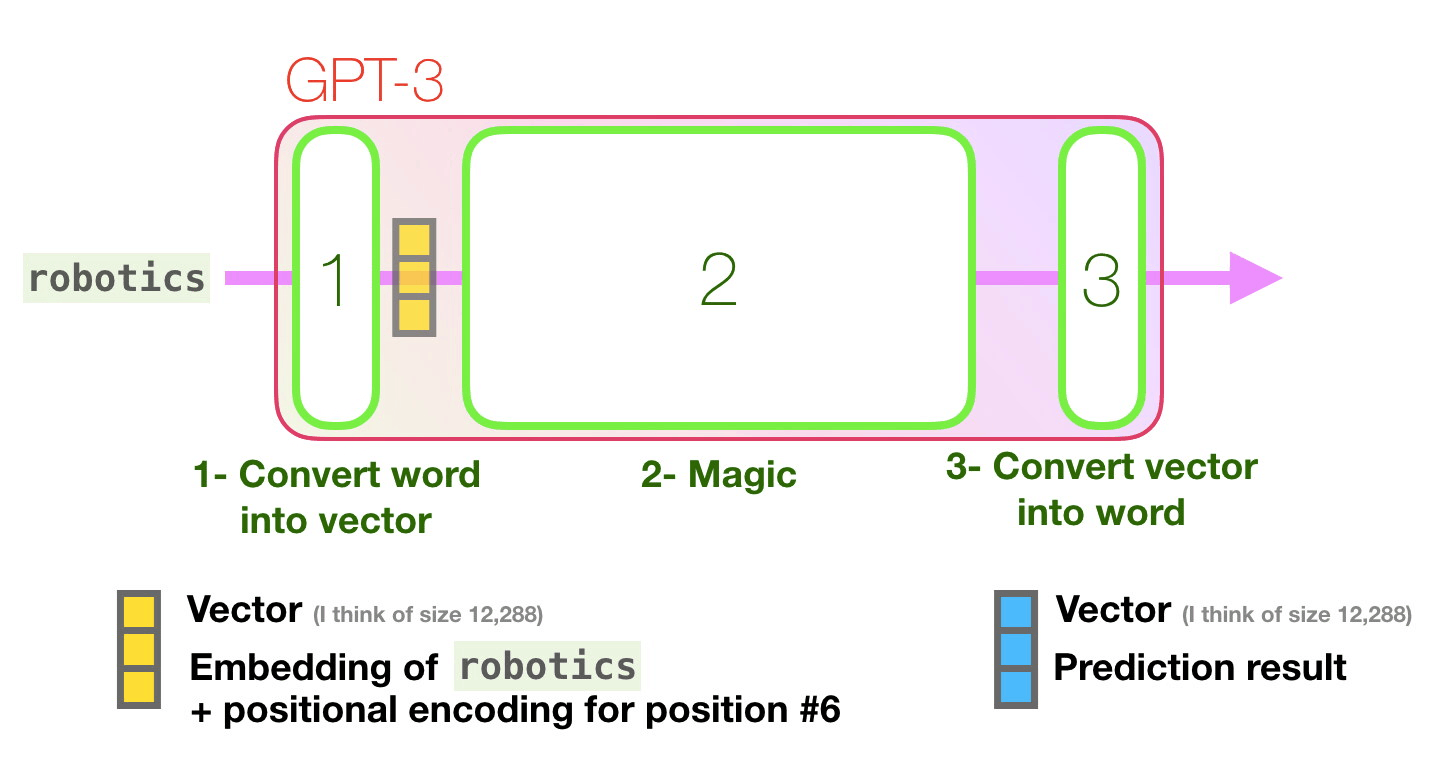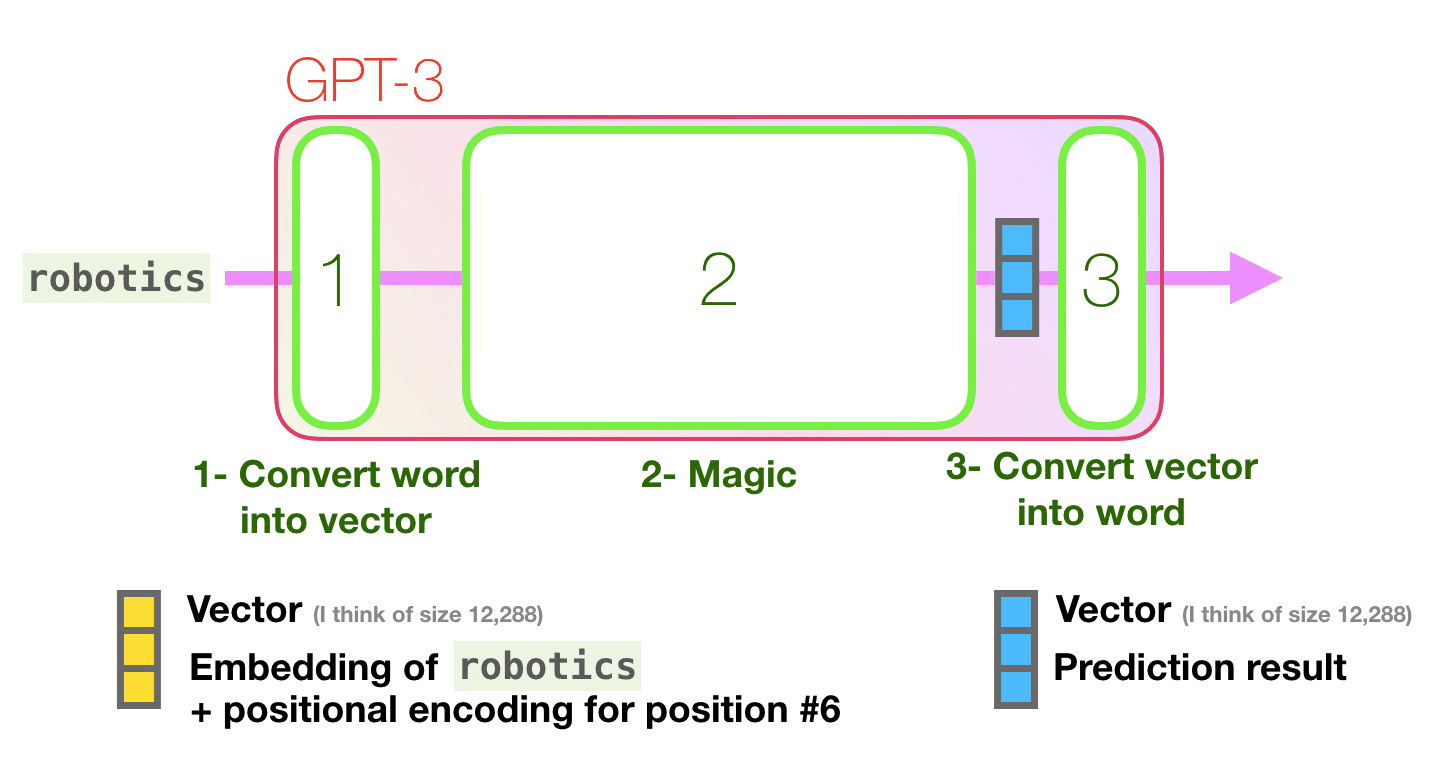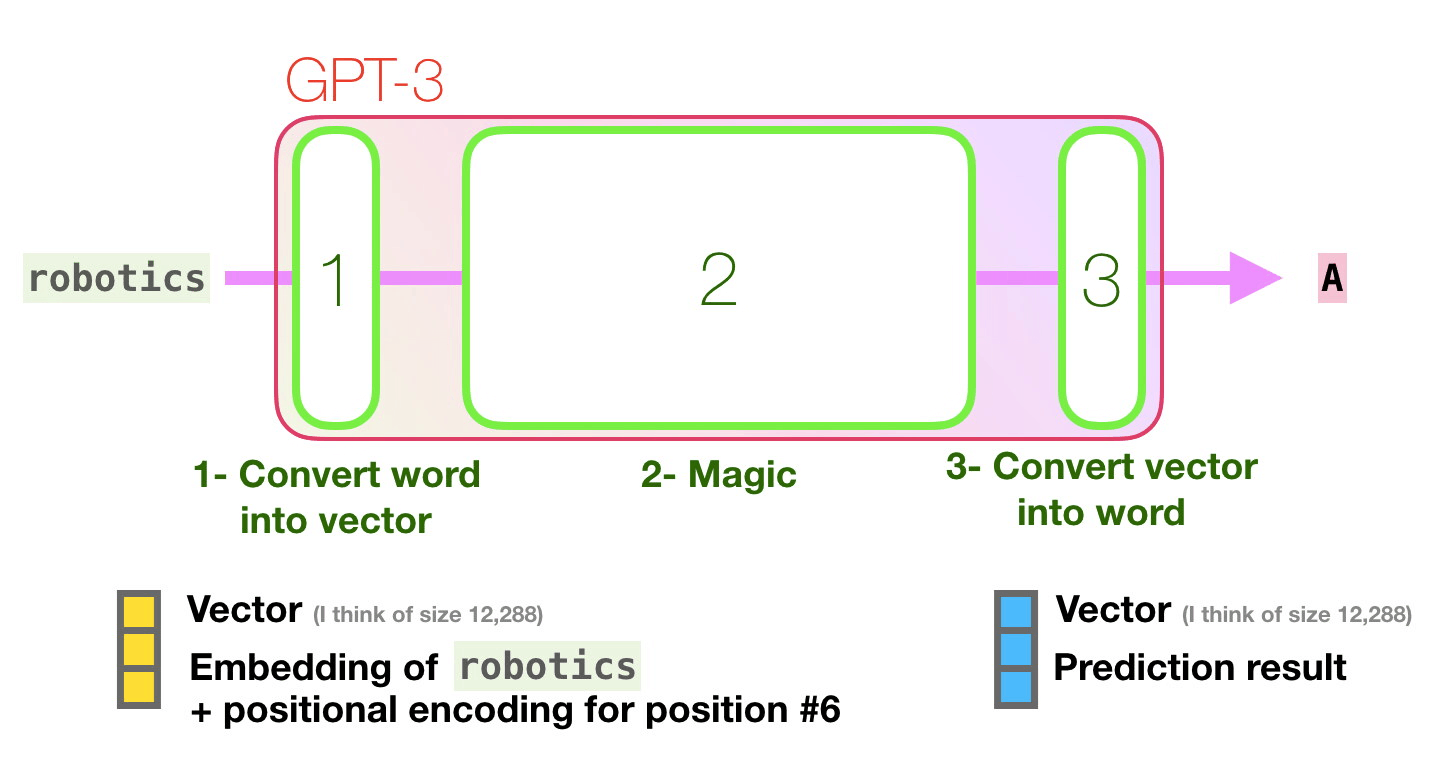
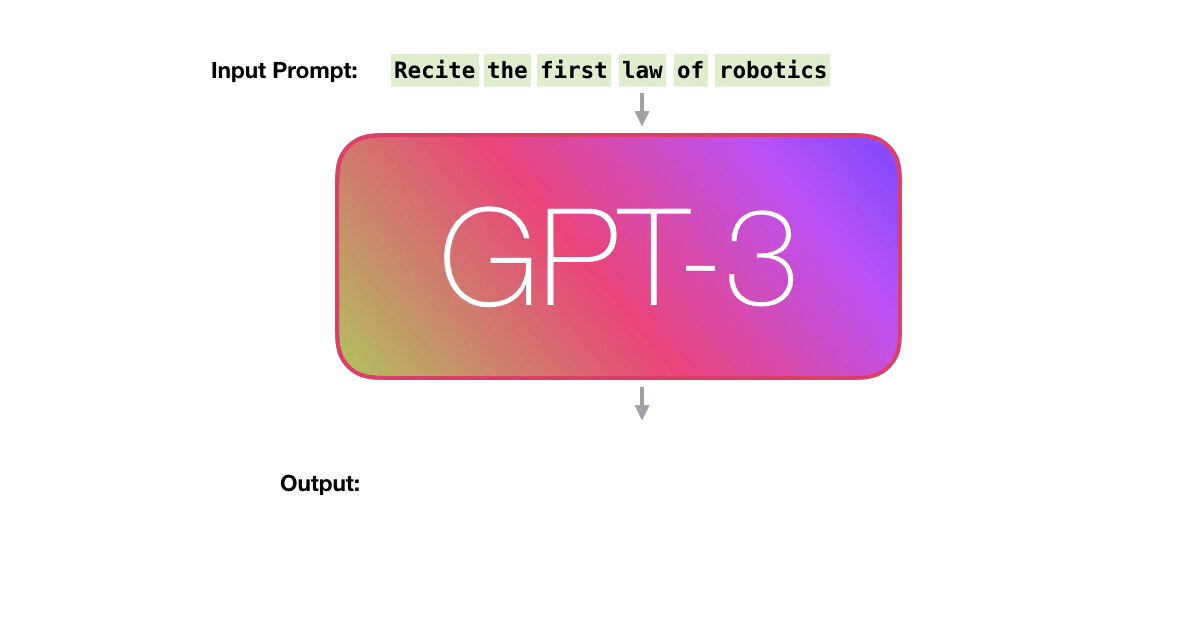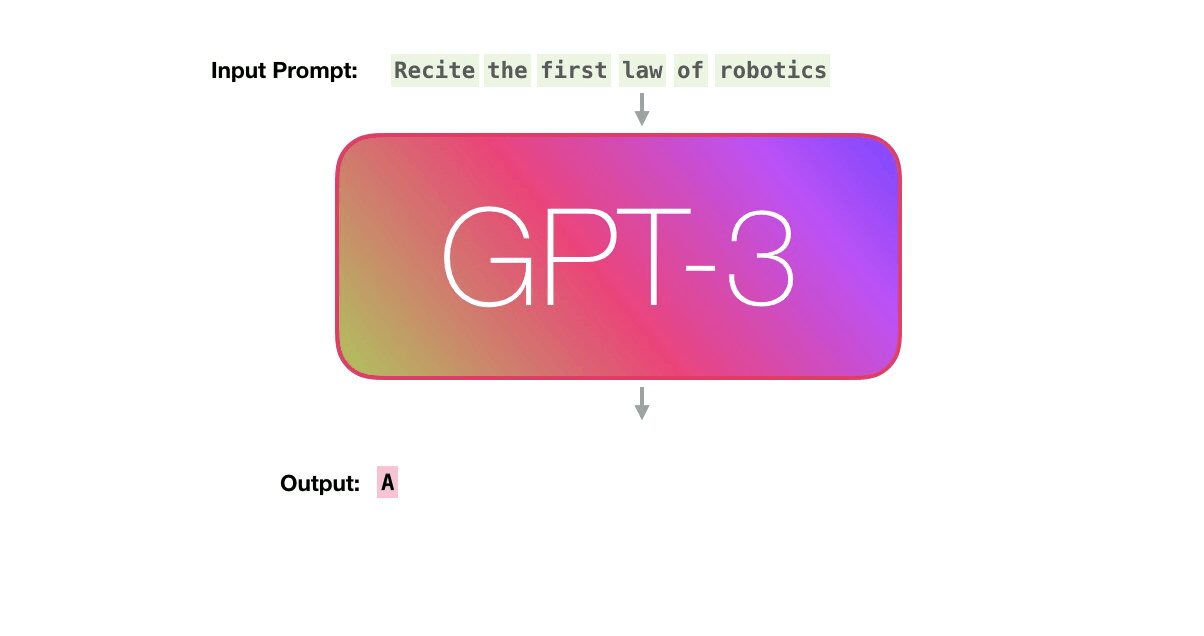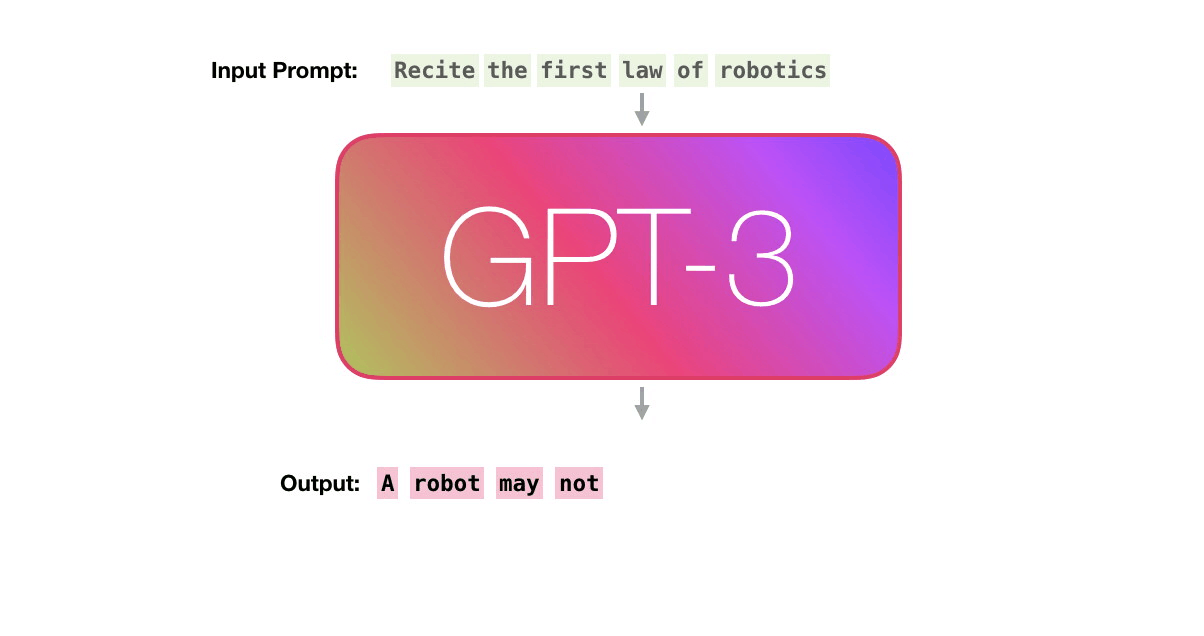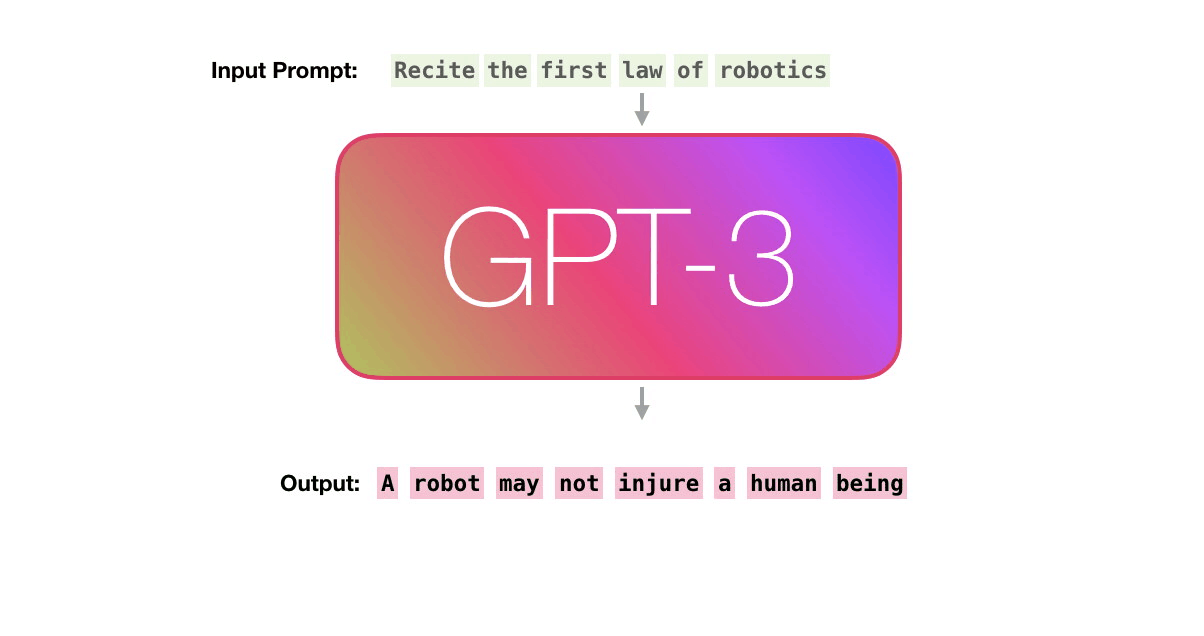
Let’s follow the purple track. How does a system process the word “robotics” and produce “A”?
High-level steps:
-
Convert the word to a vector (list of numbers) representing the word
-
Compute prediction
-
Convert resulting vector to word
The important calculations of the GPT3 occur inside its stack of 96 transformer decoder layers. This is the “depth” in “deep learning”. Each of these layers has its own 1.8B parameter to make its calculations. That is where the “magic” happens.
Let’s follow the purple track. How does a system process the word “robotics” and produce “A”?
High-level steps:
-
Convert the word to a vector (list of numbers) representing the word
-
Compute prediction
-
Convert resulting vector to word
GPT-3’s Potential Applications
-
Writing short fiction, poetry, press releases, jokes, technical manuals, news articles, …(semi) automated journalism
-
Text translation
-
Text Adventure Game creation/generation
-
Text summarization
-
Question answering
-
Convert plain text to and from legal English
-
Produce functional code Mathematical formulas
-
Write poetry and
-
Play Chess and Go, but not well.
-
Do very simple arithmetic
-
customer support chat bot
-
grammar assistance
-
improving search engine responses auto-generated articles (stocks, finance)
-
troll bots derailing online discussions
-
fake news
-
cheat on exams and essay assignments
GPT-3 Limitations
-
Limited common-sense and causal reasoning compared to SOTA and humans (bias towards knowledge rather than intelligence)
-
Limited Natural Language & Logical Inference, e.g. comparing sentences A and B (e.g. is word used the same way in A and B , A paraphrases B, A implies B)
-
Unsuitable for bidirectional tasks, such as Cloze
-
(a robot obey orders)
-
Only good for prediction tasks, not suitable for problems that require sequential decision-making and real truth grounding (acting and planning ahead)
-
Performance is unreliable and unpredictable
Future Scope
-
Larger Models: GPT-3 is still “only” 0.05% of a human brain
-
More data? We nearly reached the limit of available English text
-
Different modalities: most important: vision; speech I/O is solved
-
Other languages: for translation, non-English conversation, culture- specific knowledge
-
More data-efficient training: humans 1000x more efficient
-
Lifelong learning: online, fine-tuning